Cremi Example
This tutorial demonstrates some simple pipelines using the dacapo_toolbox dataset on cremi data. We’ll cover a fun method for instance segmentation using a 2.5D U-Net.
Introduction and overview
In this tutorial we will cover a few basic ML tasks using the DaCapo toolbox. We will:
Prepare a dataloader for the CREMI dataset
Train a simple 2D U-Net for both instance and semantic segmentation
Visualize the results
Environment setup
If you have not already done so, you will need to install DaCapo. You can do this by first creating a new environment and then installing the DaCapo Toolbox.
I highly recommend using uv for environment management, but there are many tools to choose from.
uv init
uv add git+https://github.com/pattonw/dacapo-toolbox.git
Data Preparation
DaCapo works with zarr, so we will download CREMI Sample A and save it as a zarr file.
[1]:
import multiprocessing as mp
mp.set_start_method("fork", force=True)
import dask
dask.config.set(scheduler="single-threaded")
from pathlib import Path
from functools import partial
from tqdm import tqdm
from funlib.persistence import Array
from funlib.geometry import Coordinate, Roi
from dacapo_toolbox.sample_datasets import cremi
if not Path("_static/cremi").exists():
Path("_static/cremi").mkdir(parents=True, exist_ok=True)
raw_train, labels_train, raw_test, labels_test = cremi(Path("cremi.zarr"))
# define some variables that we will use later
# The number of iterations we will train
NUM_ITERATIONS = 300
# A reasonable block size for processing image data with a UNet
blocksize = Coordinate(32, 256, 256)
# We choose a small and large eval roi for performance evaluation
# The small roi will be processed in memory, the large will be processed blockwise
offset = Coordinate(78, 465, 465)
small_eval_roi = Roi(offset, blocksize) * raw_test.voxel_size
large_eval_roi = (
Roi(offset - blocksize, blocksize * Coordinate(1, 3, 3)) * raw_test.voxel_size
)
Lets visualize our train and test data
Training data
[2]:
from dacapo_toolbox.vis.preview import gif_2d, cube
[3]:
# create a 2D gif of the training data
gif_2d(
arrays={"Train Raw": raw_train, "Train Labels": labels_train},
array_types={"Train Raw": "raw", "Train Labels": "labels"},
filename="_static/cremi/training-data.gif",
title="Training Data",
fps=10,
)
cube(
arrays={"Train Raw": raw_train, "Train Labels": labels_train},
array_types={"Train Raw": "raw", "Train Labels": "labels"},
filename="_static/cremi/training-data.jpg",
title="Training Data",
)
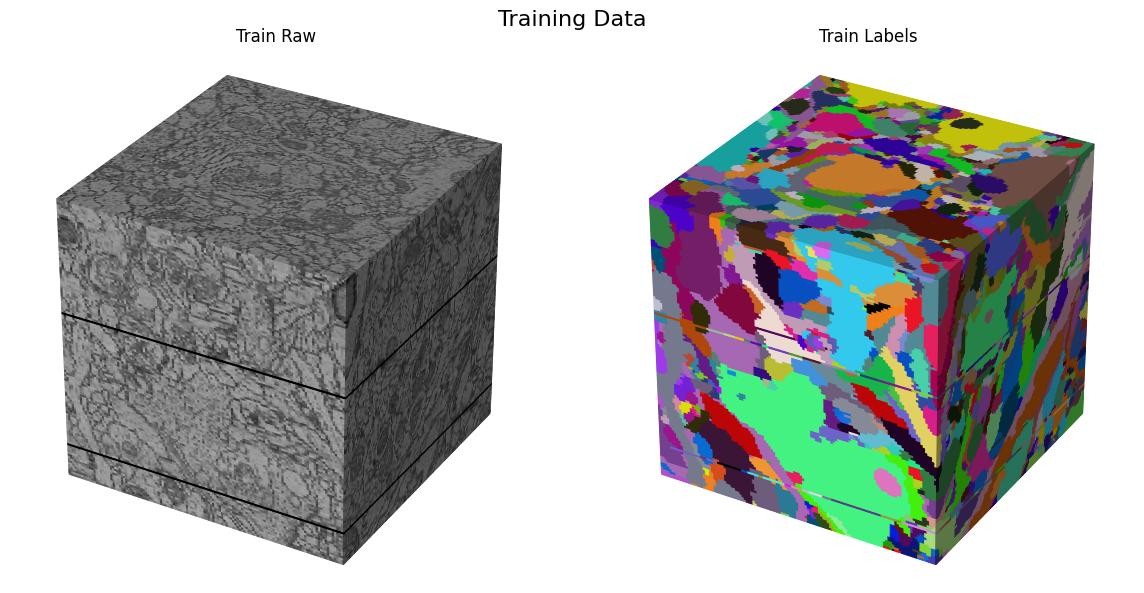
Here we visualize the training data: 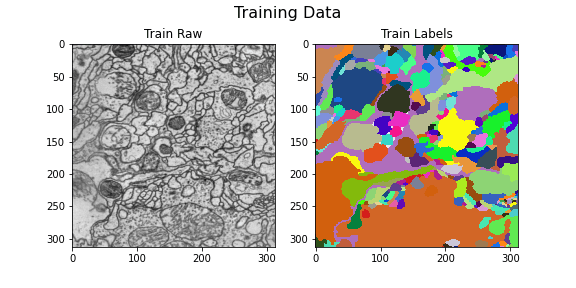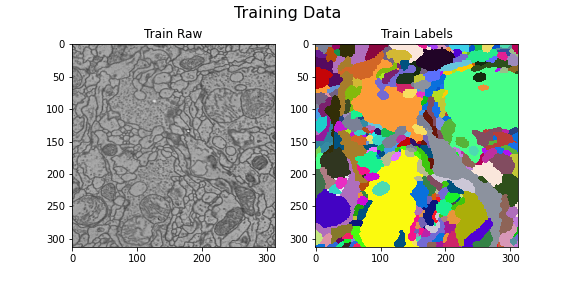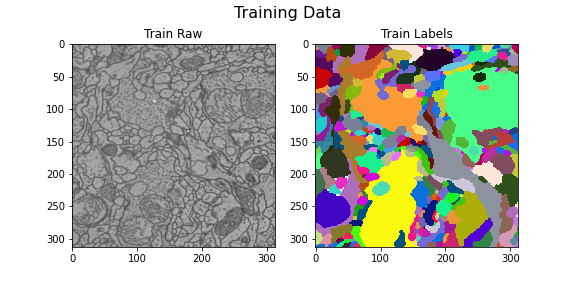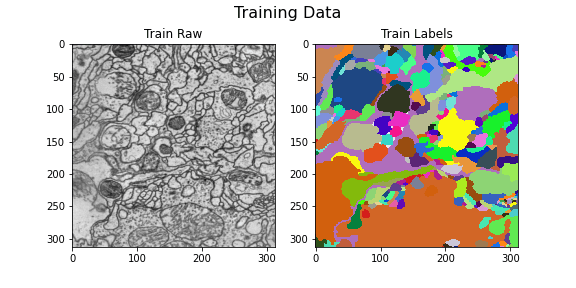
Testing data
[4]:
gif_2d(
arrays={"Test Raw": raw_test, "Test Labels": labels_test},
array_types={"Test Raw": "raw", "Test Labels": "labels"},
filename="_static/cremi/testing-data.gif",
title="Testing Data",
fps=10,
)
cube(
arrays={"Test Raw": raw_test, "Test Labels": labels_test},
array_types={"Test Raw": "raw", "Test Labels": "labels"},
filename="_static/cremi/testing-data.jpg",
title="Testing Data",
)
Here we visualize the test data: 

DaCapo
Now that we have some data, lets look at how we can use DaCapo to interface with it for some common ML use cases.
Data Split
We always want to be explicit when we define our data split for training and validation so that we are aware what data is being used for training and validation.
[5]:
from dacapo_toolbox.dataset import (
iterable_dataset,
DeformAugmentConfig,
SimpleAugmentConfig,
)
/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
[6]:
train_dataset = iterable_dataset(
datasets={"raw": raw_train, "gt": labels_train},
shapes={"raw": (13, 256, 256), "gt": (13, 256, 256)},
deform_augment_config=DeformAugmentConfig(
p=0.1,
control_point_spacing=(2, 10, 10),
jitter_sigma=(0.5, 2, 2),
rotate=True,
subsample=4,
rotation_axes=(1, 2),
scale_interval=(1.0, 1.0),
),
simple_augment_config=SimpleAugmentConfig(
p=1.0,
mirror_only=(1, 2),
transpose_only=(1, 2),
),
trim=Coordinate(5, 5, 5),
)
batch_gen = iter(train_dataset)
/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/gunpowder/nodes/deform_augment.py:164: UserWarning: Rotating with anisotropic control point spacingmay lead to exaggerated stretching.
warnings.warn(
[7]:
batch = next(batch_gen)
gif_2d(
arrays={
"Raw": Array(batch["raw"].numpy(), voxel_size=raw_train.voxel_size),
"Labels": Array(batch["gt"].numpy(), voxel_size=labels_train.voxel_size),
},
array_types={"Raw": "raw", "Labels": "labels"},
filename="_static/cremi/simple-batch.gif",
title="Simple Batch",
fps=10,
)
cube(
arrays={
"Raw": Array(batch["raw"].numpy(), voxel_size=raw_train.voxel_size),
"Labels": Array(batch["gt"].numpy(), voxel_size=labels_train.voxel_size),
},
array_types={"Raw": "raw", "Labels": "labels"},
filename="_static/cremi/simple-batch.jpg",
title="Simple Batch",
)
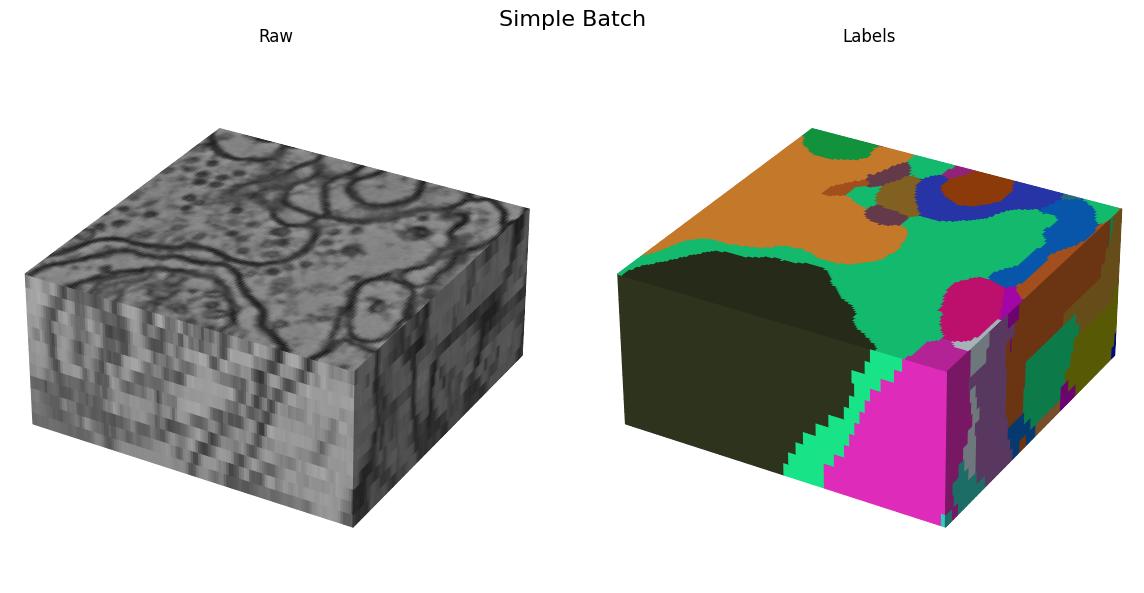
Here we visualize the training data: 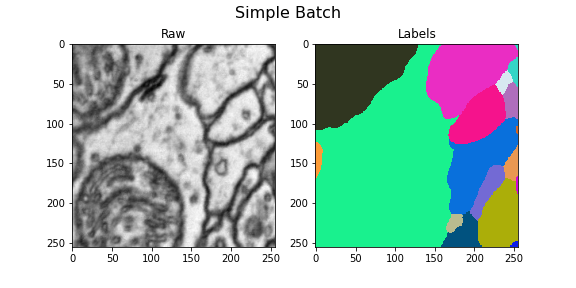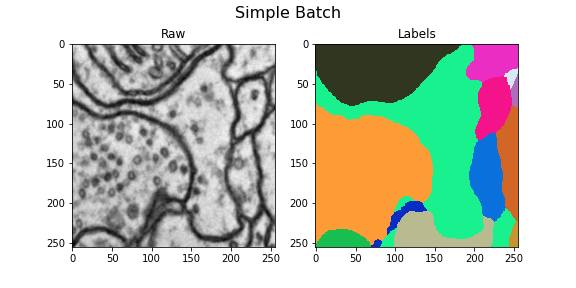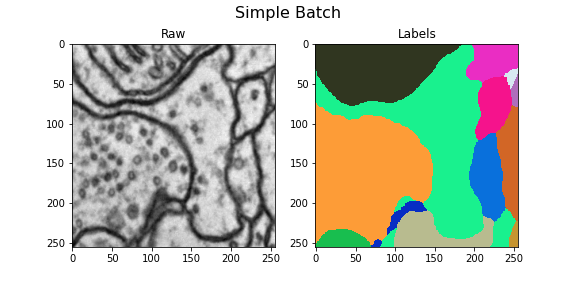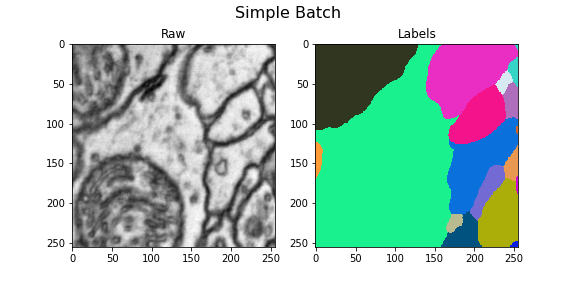
Tasks
When training for instance segmentation, it is not possible to directly predict label ids since the ids have to be unique accross the full volume which is not possible to do with the local context that a UNet operates on. So instead we need to transform our labels into some intermediate representation that is both easy to predict and easy to post process. The most common method we use is a combination of affinities with optional lsds for prediction plus mutex watershed for post processing.
Next we will define the task that encapsulates this process.
[8]:
from dacapo_toolbox.transforms.affs import Affs, AffsMask
from dacapo_toolbox.transforms.weight_balancing import BalanceLabels
import torchvision
neighborhood = [
(1, 0, 0),
(0, 1, 0),
(0, 0, 1),
(0, 7, 0),
(0, 0, 7),
(0, 23, 0),
(0, 0, 23),
]
train_dataset = iterable_dataset(
datasets={"raw": raw_train, "gt": labels_train},
shapes={"raw": (13, 256, 256), "gt": (13, 256, 256)},
transforms={
("gt", "affs"): Affs(neighborhood=neighborhood, concat_dim=0),
("gt", "affs_mask"): AffsMask(neighborhood=neighborhood),
},
deform_augment_config=DeformAugmentConfig(
p=0.1,
control_point_spacing=(2, 10, 10),
jitter_sigma=(0.5, 2, 2),
rotate=True,
subsample=4,
rotation_axes=(1, 2),
scale_interval=(1.0, 1.0),
),
simple_augment_config=SimpleAugmentConfig(
p=1.0,
mirror_only=(1, 2),
transpose_only=(1, 2),
),
)
batch_gen = iter(train_dataset)
/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/gunpowder/nodes/deform_augment.py:164: UserWarning: Rotating with anisotropic control point spacingmay lead to exaggerated stretching.
warnings.warn(
[9]:
batch = next(batch_gen)
gif_2d(
arrays={
"Raw": Array(batch["raw"].numpy(), voxel_size=raw_train.voxel_size),
"GT": Array(batch["gt"].numpy() % 256, voxel_size=raw_train.voxel_size),
"Affs": Array(
batch["affs"].float().numpy()[[0, 3, 4]],
voxel_size=raw_train.voxel_size,
),
"Affs Mask": Array(
batch["affs_mask"].float().numpy()[[0, 3, 4]],
voxel_size=raw_train.voxel_size,
),
},
array_types={
"Raw": "raw",
"GT": "labels",
"Affs": "affs",
"Affs Mask": "affs",
},
filename="_static/cremi/affs-batch.gif",
title="Affinities Batch",
fps=10,
)
cube(
arrays={
"Raw": Array(batch["raw"].numpy(), voxel_size=raw_train.voxel_size),
"GT": Array(batch["gt"].numpy(), voxel_size=raw_train.voxel_size),
"Affs": Array(
batch["affs"].float().numpy()[[0, 3, 4]],
voxel_size=raw_train.voxel_size,
),
"Affs Mask": Array(
batch["affs_mask"].float().numpy()[[0, 3, 4]],
voxel_size=raw_train.voxel_size,
),
},
array_types={
"Raw": "raw",
"GT": "labels",
"Affs": "affs",
"Affs Mask": "affs",
},
filename="_static/cremi/affs-batch.jpg",
title="Affinities Batch",
)
Here we visualize a batch with (raw, gt, target) triplets for the affinities task: 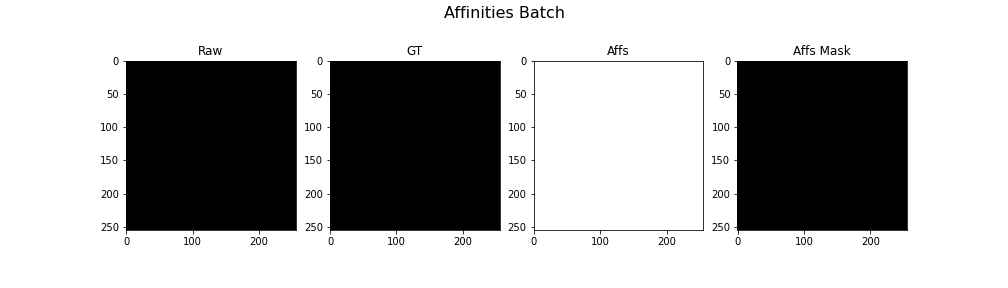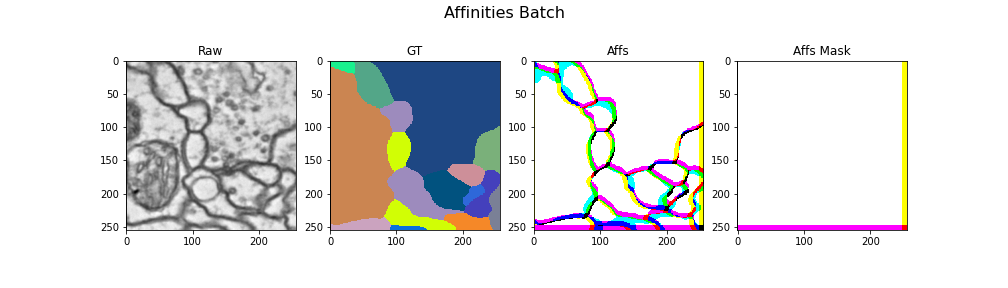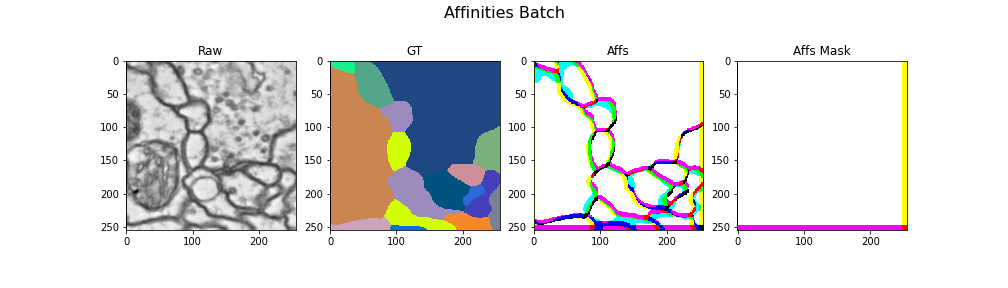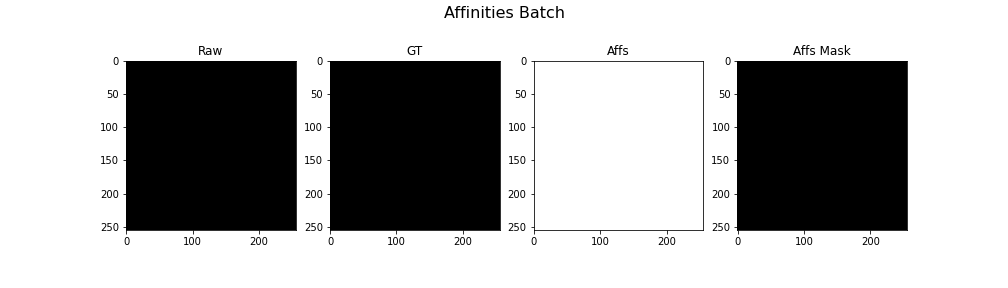
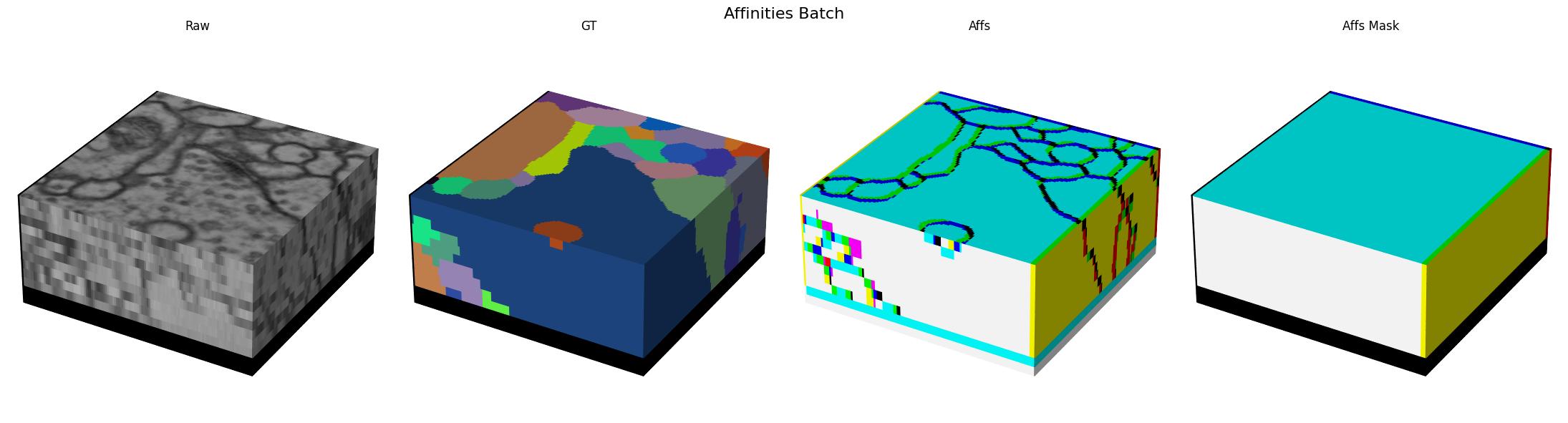
Models
Lets define our model
[10]:
import tems
import torch
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("cpu")
else:
device = torch.device("cpu")
unet = tems.UNet.funlib_api(
dims=3,
in_channels=1,
num_fmaps=32,
fmap_inc_factor=4,
downsample_factors=[(1, 2, 2), (1, 2, 2), (1, 2, 2)],
kernel_size_down=[
[(1, 3, 3), (1, 3, 3)],
[(1, 3, 3), (1, 3, 3)],
[(1, 3, 3), (1, 3, 3)],
[(1, 3, 3), (1, 3, 3)],
],
kernel_size_up=[
[(1, 3, 3), (1, 3, 3)],
[(1, 3, 3), (1, 3, 3)],
[(3, 3, 3), (3, 3, 3)],
],
activation="LeakyReLU",
)
# Small sigmoid wrapper to apply sigmoid only when not training
# this is because training BCEWithLogitsLoss is more stable
# than training with a sigmoid followed by BCELoss
class SigmoidWrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
self.apply_sigmoid = True
def forward(self, x):
logits = self.model(x)
if self.apply_sigmoid and not self.training:
return torch.sigmoid(logits)
return logits
module = SigmoidWrapper(
torch.nn.Sequential(unet, torch.nn.Conv3d(32, len(neighborhood), kernel_size=1))
).to(device)
Training loop
Now we can bring everything together and train our model.
[11]:
import torch
extra = torch.tensor((2, 64, 64))
train_dataset = iterable_dataset(
datasets={"raw": raw_train, "gt": labels_train},
shapes={
"raw": unet.min_input_shape + extra,
"gt": unet.min_output_shape + extra,
},
transforms={
"raw": torchvision.transforms.Lambda(lambda x: x[None].float() / 255.0),
("gt", "affs"): Affs(neighborhood=neighborhood, concat_dim=0),
("gt", "affs_mask"): AffsMask(neighborhood=neighborhood),
},
deform_augment_config=DeformAugmentConfig(
p=0.1,
control_point_spacing=(2, 10, 10),
jitter_sigma=(0.5, 2, 2),
rotate=True,
subsample=4,
rotation_axes=(1, 2),
scale_interval=(1.0, 1.0),
),
simple_augment_config=SimpleAugmentConfig(
p=1.0,
mirror_only=(1, 2),
transpose_only=(1, 2),
),
)
loss_func = partial(torchvision.ops.sigmoid_focal_loss, reduction="none")
optimizer = torch.optim.Adam(module.parameters(), lr=5e-5)
dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=3,
num_workers=4,
)
losses = []
for iteration, batch in tqdm(enumerate(iter(dataloader))):
raw, target, affs_mask = (
batch["raw"].to(device),
batch["affs"].to(device),
batch["affs_mask"].to(device),
)
optimizer.zero_grad()
output = module(raw)
voxel_loss = loss_func(output, target.float())
loss = (voxel_loss * affs_mask).sum() / affs_mask.sum()
loss.backward()
optimizer.step()
losses.append(loss.item())
if iteration >= NUM_ITERATIONS:
break
/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/gunpowder/nodes/deform_augment.py:164: UserWarning: Rotating with anisotropic control point spacingmay lead to exaggerated stretching.
warnings.warn(
300it [1:46:27, 21.29s/it]
[12]:
import matplotlib.pyplot as plt
from funlib.geometry import Coordinate
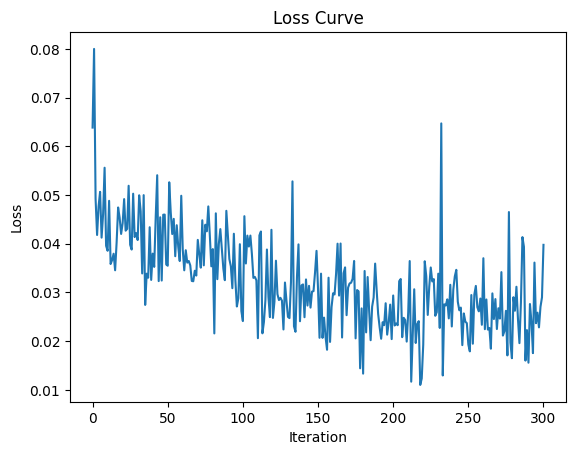
plt.plot(losses)
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.savefig("_static/cremi/affs-loss-curve.png")
plt.show()
plt.close()
[13]:
import mwatershed as mws
from funlib.geometry import Roi
import numpy as np
module = module.eval()
unet = unet.eval()
context = Coordinate(unet.context // 2) * raw_test.voxel_size
[14]:
raw_input = raw_test.to_ndarray(small_eval_roi.grow(context, context))
raw_output = raw_test.to_ndarray(small_eval_roi)
gt = labels_test.to_ndarray(small_eval_roi)
# Predict on the validation data
with torch.no_grad():
device = torch.device("cpu")
module = module.to(device)
pred = (
module(
(torch.from_numpy(raw_input).float() / 255.0)
.to(device)
.unsqueeze(0)
.unsqueeze(0)
)
.cpu()
.detach()
.numpy()
)
pred_labels = mws.agglom(pred[0].astype(np.float64) - 0.5, offsets=neighborhood)
[15]:
# Plot the results
gif_2d(
arrays={
"Raw": Array(raw_output, voxel_size=raw_test.voxel_size),
"GT": Array(gt % 256, voxel_size=raw_test.voxel_size),
"Pred Affs": Array(pred[0][[0, 3, 4]], voxel_size=raw_test.voxel_size),
"Pred": Array(pred_labels % 256, voxel_size=raw_test.voxel_size),
},
array_types={
"Raw": "raw",
"GT": "labels",
"Pred Affs": "affs",
"Pred": "labels",
},
filename="_static/cremi/affs-prediction.gif",
title="Prediction",
fps=10,
)
cube(
arrays={
"Raw": Array(raw_output, voxel_size=raw_test.voxel_size),
"GT": Array(gt, voxel_size=raw_test.voxel_size),
"Pred Affs": Array(pred[0][[0, 3, 4]], voxel_size=raw_test.voxel_size),
"Pred": Array(pred_labels, voxel_size=raw_test.voxel_size),
},
array_types={
"Raw": "raw",
"GT": "labels",
"Pred Affs": "affs",
"Pred": "labels",
},
filename="_static/cremi/affs-prediction.jpg",
title="Prediction",
)
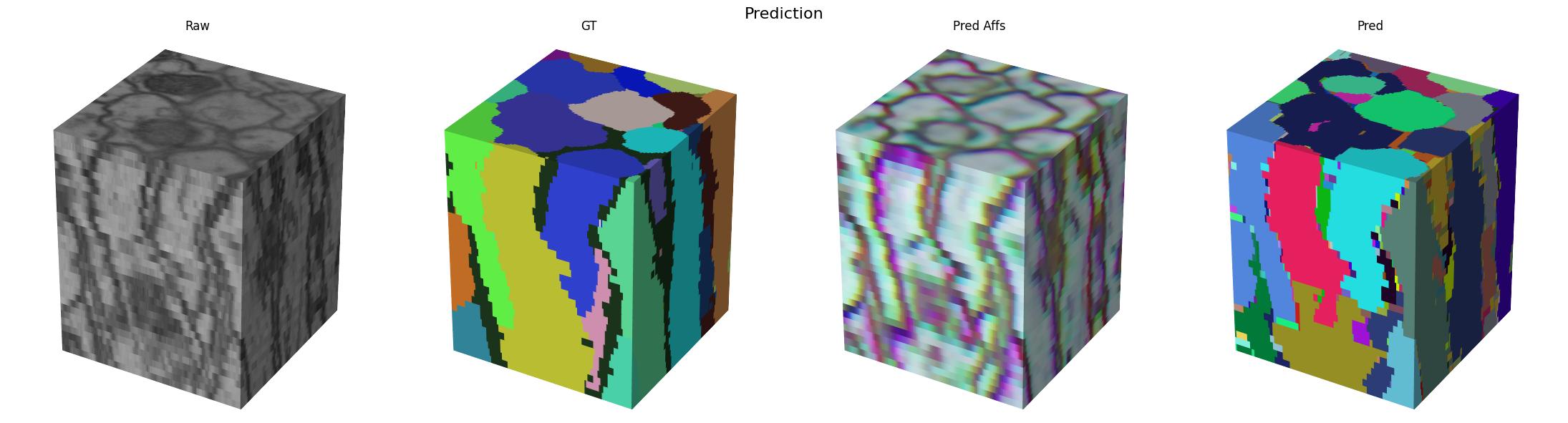
Here we visualize the prediction results: 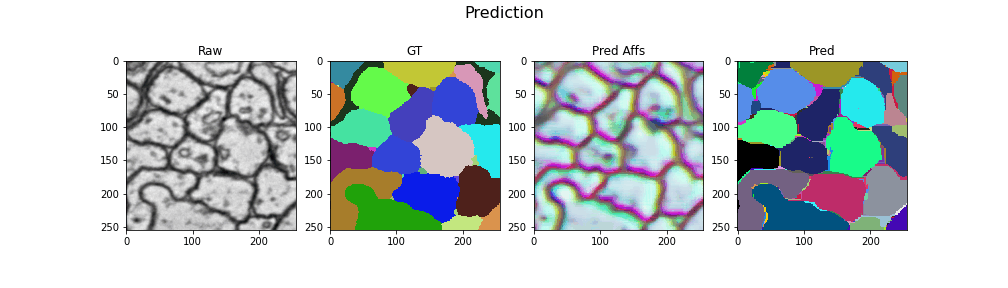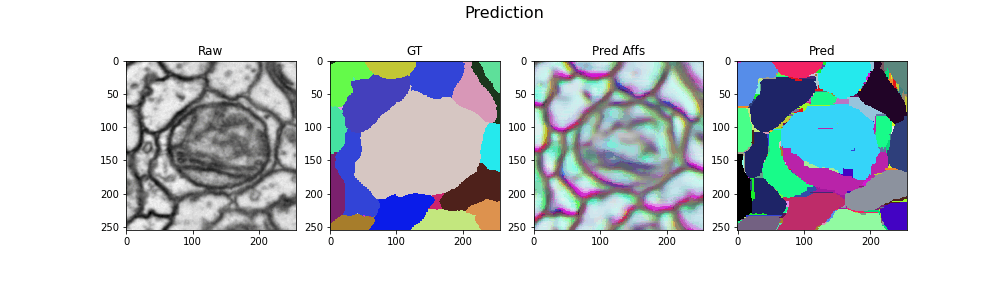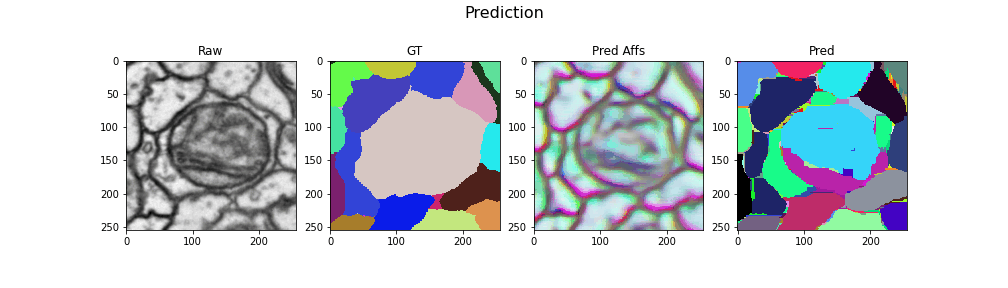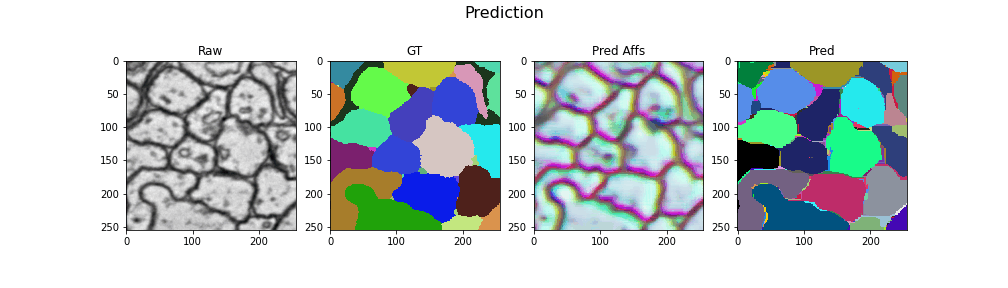
Blockwise Processing
Now that we have a trained model, we can use it to process the full volume. We will use the volara library to do this. It provides a simple interface for blockwise processing of large volumes. We will use the volara_torch module to wrap our trained model and use it in a blockwise pipeline.
[16]:
from dacapo_toolbox.postprocessing import blockwise_predict_mutex
from volara.workers import LocalWorker
unet = unet.eval()
scripted_unet = torch.jit.script(module)
torch.jit.save(scripted_unet, "cremi.zarr/affs_unet.pt")
torch.save(scripted_unet.state_dict(), "cremi.zarr/weights.pth")
blocksize = Coordinate(unet.min_output_shape) + blocksize
# default biases:
# interpolate log offset distances to a range of [-0.2, -0.8]
blockwise_predict_mutex(
raw_store="cremi.zarr/test/raw",
affs_store="cremi.zarr/test/affs", # optional, provided for visualization
frags_store="cremi.zarr/test/frags", # optional, provided for visualization
labels_store="cremi.zarr/test/pred_labels",
neighborhood=neighborhood,
blocksize=blocksize,
model_path="cremi.zarr/affs_unet.pt",
in_channels=1,
model_context=unet.context // 2,
predict_worker=LocalWorker(), # optional, see docstring
extract_frag_bias=[
-0.5,
-0.2,
-0.2,
-0.5,
-0.5,
-0.8,
-0.8,
], # optional, TODO: defaults not very good yet
edge_scores=[ # optional, TODO: defaults not very good yet
("affs_z", [Coordinate(1, 0, 0)], -0.5),
("affs_xy", [Coordinate(0, 1, 0), Coordinate(0, 0, 1)], -0.2),
(
"affs_long_xy",
[
Coordinate(0, 7, 0),
Coordinate(0, 0, 7),
Coordinate(0, 23, 0),
Coordinate(0, 0, 23),
],
-0.8,
),
],
num_extract_frag_workers=3,
num_aff_agglom_workers=3,
num_relabel_workers=3,
roi=large_eval_roi,
)
INFO:root:Running block with config volara_logs/affs-predict-meta/config.json...
INFO:funlib.persistence.graphs.sqlite_graph_database:dropping collections nodes, edges
/tmp/tmpjdjr1ign/lut.npz
affs-predict ▶: 56%|█████▌ | 5/9 [11:35<09:15, 139.00s/blocks, ⧗=0, ▶=1, ✔=5, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 0%| | 0/9 [00:00<?, ?blocks/s]INFO:volara.blockwise.blockwise:got block frags-extract-frags/0 with read ROI [1760:3200, 652:2076, 652:2076] (1440, 1424, 1424) and write ROI [1840:3120, 836:1892, 836:1892] (1280, 1056, 1056)
frags-extract-frags ▶: 0%| | 0/9 [00:00<?, ?blocks/s, ⧗=8, ▶=1, ✔=0, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:getting block
INFO:volara.blockwise.blockwise:getting block
INFO:/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/volara/blockwise/extract_frags.py:Found 876 fragments
INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 0%| | 0/9 [00:07<?, ?blocks/s, ⧗=8, ▶=0, ✔=1, ✗=0, ∅=0]
affs-predict ▶: 67%|██████▋ | 6/9 [13:57<07:00, 140.19s/blocks, ⧗=0, ▶=1, ✔=6, ✗=0, ∅=0]
frags-extract-frags ▶: 11%|█ | 1/9 [02:22<01:03, 7.95s/blocks, ⧗=6, ▶=1, ✔=1, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block frags-extract-frags/1 with read ROI [1760:3200, 652:2076, 1708:3132] (1440, 1424, 1424) and write ROI [1840:3120, 836:1892, 1892:2948] (1280, 1056, 1056)
frags-extract-frags ▶: 11%|█ | 1/9 [02:22<01:03, 7.95s/blocks, ⧗=6, ▶=2, ✔=1, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block frags-extract-frags/4 with read ROI [1760:3200, 652:2076, 2764:4092] (1440, 1424, 1328) and write ROI [1840:3120, 836:1892, 2948:3908] (1280, 1056, 960)
INFO:/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/volara/blockwise/extract_frags.py:Found 881 fragments
INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 11%|█ | 1/9 [02:34<01:03, 7.95s/blocks, ⧗=6, ▶=1, ✔=2, ✗=0, ∅=0]
frags-extract-frags ▶: 22%|██▏ | 2/9 [02:34<10:24, 89.28s/blocks, ⧗=6, ▶=1, ✔=2, ✗=0, ∅=0]INFO:/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/volara/blockwise/extract_frags.py:Found 857 fragments
INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 22%|██▏ | 2/9 [02:35<10:24, 89.28s/blocks, ⧗=6, ▶=0, ✔=3, ✗=0, ∅=0]
affs-predict ▶: 89%|████████▉ | 8/9 [18:37<02:20, 140.06s/blocks, ⧗=0, ▶=1, ✔=8, ✗=0, ∅=0]
frags-extract-frags ▶: 33%|███▎ | 3/9 [07:02<04:53, 48.94s/blocks, ⧗=4, ▶=1, ✔=3, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block frags-extract-frags/2 with read ROI [1760:3200, 1708:3132, 652:2076] (1440, 1424, 1424) and write ROI [1840:3120, 1892:2948, 836:1892] (1280, 1056, 1056)
INFO:volara.blockwise.blockwise:got block frags-extract-frags/7 with read ROI [1760:3200, 2764:4092, 652:2076] (1440, 1328, 1424) and write ROI [1840:3120, 2948:3908, 836:1892] (1280, 960, 1056)
frags-extract-frags ▶: 33%|███▎ | 3/9 [07:02<04:53, 48.94s/blocks, ⧗=4, ▶=2, ✔=3, ✗=0, ∅=0]INFO:/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/volara/blockwise/extract_frags.py:Found 821 fragments
INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 33%|███▎ | 3/9 [07:14<04:53, 48.94s/blocks, ⧗=4, ▶=1, ✔=4, ✗=0, ∅=0]
frags-extract-frags ▶: 44%|████▍ | 4/9 [07:14<11:39, 139.85s/blocks, ⧗=4, ▶=1, ✔=4, ✗=0, ∅=0]INFO:/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/volara/blockwise/extract_frags.py:Found 851 fragments
INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 44%|████▍ | 4/9 [07:15<11:39, 139.85s/blocks, ⧗=4, ▶=0, ✔=5, ✗=0, ∅=0]
affs-predict ✔: 100%|██████████| 9/9 [20:58<00:00, 139.86s/blocks, ⧗=0, ▶=0, ✔=9, ✗=0, ∅=0]
frags-extract-frags ▶: 56%|█████▌ | 5/9 [09:23<05:59, 89.94s/blocks, ⧗=0, ▶=1, ✔=5, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block frags-extract-frags/5 with read ROI [1760:3200, 1708:3132, 1708:3132] (1440, 1424, 1424) and write ROI [1840:3120, 1892:2948, 1892:2948] (1280, 1056, 1056)
frags-extract-frags ▶: 56%|█████▌ | 5/9 [09:23<05:59, 89.94s/blocks, ⧗=0, ▶=2, ✔=5, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block frags-extract-frags/11 with read ROI [1760:3200, 1708:3132, 2764:4092] (1440, 1424, 1328) and write ROI [1840:3120, 1892:2948, 2948:3908] (1280, 1056, 960)
frags-extract-frags ▶: 56%|█████▌ | 5/9 [09:23<05:59, 89.94s/blocks, ⧗=0, ▶=3, ✔=5, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block frags-extract-frags/13 with read ROI [1760:3200, 2764:4092, 1708:3132] (1440, 1328, 1424) and write ROI [1840:3120, 2948:3908, 1892:2948] (1280, 960, 1056)
INFO:/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/volara/blockwise/extract_frags.py:Found 948 fragments
INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 56%|█████▌ | 5/9 [09:33<05:59, 89.94s/blocks, ⧗=0, ▶=2, ✔=6, ✗=0, ∅=0]
frags-extract-frags ▶: 67%|██████▋ | 6/9 [09:33<05:18, 106.09s/blocks, ⧗=0, ▶=2, ✔=6, ✗=0, ∅=0]
frags-extract-frags ▶: 67%|██████▋ | 6/9 [09:33<05:18, 106.09s/blocks, ⧗=0, ▶=3, ✔=6, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block frags-extract-frags/23 with read ROI [1760:3200, 2764:4092, 2764:4092] (1440, 1328, 1328) and write ROI [1840:3120, 2948:3908, 2948:3908] (1280, 960, 960)
INFO:/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/volara/blockwise/extract_frags.py:Found 896 fragments
INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 67%|██████▋ | 6/9 [09:36<05:18, 106.09s/blocks, ⧗=0, ▶=2, ✔=7, ✗=0, ∅=0]
frags-extract-frags ▶: 78%|███████▊ | 7/9 [09:36<02:25, 72.56s/blocks, ⧗=0, ▶=2, ✔=7, ✗=0, ∅=0] INFO:volara.blockwise.blockwise:got block None
INFO:/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/volara/blockwise/extract_frags.py:Found 902 fragments
INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 78%|███████▊ | 7/9 [09:37<02:25, 72.56s/blocks, ⧗=0, ▶=1, ✔=8, ✗=0, ∅=0]
frags-extract-frags ▶: 89%|████████▉ | 8/9 [09:37<00:49, 49.74s/blocks, ⧗=0, ▶=1, ✔=8, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 0%| | 0/9 [00:00<?, ?blocks/s]INFO:volara.blockwise.blockwise:got block fragments-aff-agglom/0 with read ROI [1800:3160, 744:1984, 744:1984] (1360, 1240, 1240) and write ROI [1840:3120, 836:1892, 836:1892] (1280, 1056, 1056)
fragments-aff-agglom ▶: 0%| | 0/9 [00:00<?, ?blocks/s, ⧗=4, ▶=1, ✔=0, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 0%| | 0/9 [00:00<?, ?blocks/s, ⧗=4, ▶=2, ✔=0, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block fragments-aff-agglom/1 with read ROI [1800:3160, 744:1984, 1800:3040] (1360, 1240, 1240) and write ROI [1840:3120, 836:1892, 1892:2948] (1280, 1056, 1056)
INFO:volara.blockwise.blockwise:got block None
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 0%| | 0/9 [00:00<?, ?blocks/s, ⧗=4, ▶=3, ✔=0, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block fragments-aff-agglom/2 with read ROI [1800:3160, 1800:3040, 744:1984] (1360, 1240, 1240) and write ROI [1840:3120, 1892:2948, 836:1892] (1280, 1056, 1056)
INFO:/home/runner/work/dacapo-toolbox/dacapo-toolbox/.venv/lib/python3.11/site-packages/volara/blockwise/extract_frags.py:Found 871 fragments
INFO:volara.blockwise.blockwise:getting block
frags-extract-frags ▶: 89%|████████▉ | 8/9 [09:44<00:49, 49.74s/blocks, ⧗=0, ▶=0, ✔=9, ✗=0, ∅=0]
frags-extract-frags ▶: 100%|██████████| 9/9 [09:44<00:00, 36.28s/blocks, ⧗=0, ▶=0, ✔=9, ✗=0, ∅=0]
frags-extract-frags ✔: 100%|██████████| 9/9 [09:44<00:00, 64.92s/blocks, ⧗=0, ▶=0, ✔=9, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block None
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 11%|█ | 1/9 [00:09<01:18, 9.80s/blocks, ⧗=0, ▶=3, ✔=1, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block fragments-aff-agglom/4 with read ROI [1800:3160, 744:1984, 2856:4000] (1360, 1240, 1144) and write ROI [1840:3120, 836:1892, 2948:3908] (1280, 1056, 960)
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 22%|██▏ | 2/9 [00:11<00:33, 4.82s/blocks, ⧗=0, ▶=3, ✔=2, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block fragments-aff-agglom/7 with read ROI [1800:3160, 2856:4000, 744:1984] (1360, 1144, 1240) and write ROI [1840:3120, 2948:3908, 836:1892] (1280, 960, 1056)
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 33%|███▎ | 3/9 [00:12<00:18, 3.09s/blocks, ⧗=0, ▶=3, ✔=3, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block fragments-aff-agglom/5 with read ROI [1800:3160, 1800:3040, 1800:3040] (1360, 1240, 1240) and write ROI [1840:3120, 1892:2948, 1892:2948] (1280, 1056, 1056)
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 44%|████▍ | 4/9 [00:19<00:23, 4.63s/blocks, ⧗=0, ▶=3, ✔=4, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block fragments-aff-agglom/11 with read ROI [1800:3160, 1800:3040, 2856:4000] (1360, 1240, 1144) and write ROI [1840:3120, 1892:2948, 2948:3908] (1280, 1056, 960)
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 56%|█████▌ | 5/9 [00:19<00:12, 3.01s/blocks, ⧗=0, ▶=3, ✔=5, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block fragments-aff-agglom/13 with read ROI [1800:3160, 2856:4000, 1800:3040] (1360, 1144, 1240) and write ROI [1840:3120, 2948:3908, 1892:2948] (1280, 960, 1056)
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 67%|██████▋ | 6/9 [00:25<00:12, 4.21s/blocks, ⧗=0, ▶=3, ✔=6, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block fragments-aff-agglom/23 with read ROI [1800:3160, 2856:4000, 2856:4000] (1360, 1144, 1144) and write ROI [1840:3120, 2948:3908, 2948:3908] (1280, 960, 960)
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 78%|███████▊ | 7/9 [00:27<00:06, 3.28s/blocks, ⧗=0, ▶=2, ✔=7, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block None
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ▶: 89%|████████▉ | 8/9 [00:29<00:02, 2.91s/blocks, ⧗=0, ▶=1, ✔=8, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block None
INFO:volara.blockwise.blockwise:getting block
fragments-aff-agglom ✔: 100%|██████████| 9/9 [00:32<00:00, 3.57s/blocks, ⧗=0, ▶=0, ✔=9, ✗=0, ∅=0]
INFO:volara.blockwise.blockwise:getting block
INFO:volara.blockwise.blockwise:got block None
lut-graph-mws ▶: 0%| | 0/1 [00:00<?, ?blocks/s, ⧗=0, ▶=1, ✔=0, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block lut-graph-mws/0 with read ROI [1840:3120, 836:3908, 836:3908] (1280, 3072, 3072) and write ROI [1840:3120, 836:3908, 836:3908] (1280, 3072, 3072)
INFO:volara.blockwise.blockwise:getting block
lut-graph-mws ✔: 100%|██████████| 1/1 [00:01<00:00, 1.20s/blocks, ⧗=0, ▶=0, ✔=1, ✗=0, ∅=0]
INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 0%| | 0/9 [00:00<?, ?blocks/s]INFO:volara.blockwise.blockwise:got block pred_labels-relabel/0 with read ROI [1840:3120, 836:1892, 836:1892] (1280, 1056, 1056) and write ROI [1840:3120, 836:1892, 836:1892] (1280, 1056, 1056)
pred_labels-relabel ▶: 0%| | 0/9 [00:00<?, ?blocks/s, ⧗=0, ▶=1, ✔=0, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 0%| | 0/9 [00:00<?, ?blocks/s, ⧗=0, ▶=2, ✔=0, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block pred_labels-relabel/1 with read ROI [1840:3120, 836:1892, 1892:2948] (1280, 1056, 1056) and write ROI [1840:3120, 836:1892, 1892:2948] (1280, 1056, 1056)
INFO:volara.blockwise.blockwise:got block None
INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 0%| | 0/9 [00:00<?, ?blocks/s, ⧗=0, ▶=3, ✔=0, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block pred_labels-relabel/2 with read ROI [1840:3120, 1892:2948, 836:1892] (1280, 1056, 1056) and write ROI [1840:3120, 1892:2948, 836:1892] (1280, 1056, 1056)
INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 11%|█ | 1/9 [00:03<00:25, 3.23s/blocks, ⧗=0, ▶=3, ✔=1, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block pred_labels-relabel/4 with read ROI [1840:3120, 836:1892, 2948:3908] (1280, 1056, 960) and write ROI [1840:3120, 836:1892, 2948:3908] (1280, 1056, 960)
INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 22%|██▏ | 2/9 [00:03<00:09, 1.41s/blocks, ⧗=0, ▶=3, ✔=2, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block pred_labels-relabel/5 with read ROI [1840:3120, 1892:2948, 1892:2948] (1280, 1056, 1056) and write ROI [1840:3120, 1892:2948, 1892:2948] (1280, 1056, 1056)
INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 33%|███▎ | 3/9 [00:03<00:04, 1.20blocks/s, ⧗=0, ▶=3, ✔=3, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block pred_labels-relabel/7 with read ROI [1840:3120, 2948:3908, 836:1892] (1280, 960, 1056) and write ROI [1840:3120, 2948:3908, 836:1892] (1280, 960, 1056)
INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 44%|████▍ | 4/9 [00:03<00:02, 1.79blocks/s, ⧗=0, ▶=2, ✔=4, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 56%|█████▌ | 5/9 [00:03<00:02, 1.79blocks/s, ⧗=0, ▶=2, ✔=5, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block pred_labels-relabel/11 with read ROI [1840:3120, 1892:2948, 2948:3908] (1280, 1056, 960) and write ROI [1840:3120, 1892:2948, 2948:3908] (1280, 1056, 960)
INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 67%|██████▋ | 6/9 [00:03<00:01, 1.79blocks/s, ⧗=0, ▶=2, ✔=6, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block pred_labels-relabel/13 with read ROI [1840:3120, 2948:3908, 1892:2948] (1280, 960, 1056) and write ROI [1840:3120, 2948:3908, 1892:2948] (1280, 960, 1056)
pred_labels-relabel ▶: 67%|██████▋ | 6/9 [00:03<00:01, 1.79blocks/s, ⧗=0, ▶=3, ✔=6, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:got block pred_labels-relabel/23 with read ROI [1840:3120, 2948:3908, 2948:3908] (1280, 960, 960) and write ROI [1840:3120, 2948:3908, 2948:3908] (1280, 960, 960)
pred_labels-relabel ▶: 67%|██████▋ | 6/9 [00:03<00:01, 1.79blocks/s, ⧗=0, ▶=2, ✔=7, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 78%|███████▊ | 7/9 [00:03<00:00, 4.22blocks/s, ⧗=0, ▶=2, ✔=7, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ▶: 78%|███████▊ | 7/9 [00:03<00:00, 4.22blocks/s, ⧗=0, ▶=1, ✔=8, ✗=0, ∅=0]INFO:volara.blockwise.blockwise:getting block
pred_labels-relabel ✔: 100%|██████████| 9/9 [00:03<00:00, 2.34blocks/s, ⧗=0, ▶=0, ✔=9, ✗=0, ∅=0]
INFO:volara.blockwise.blockwise:got block None
Execution Summary
-----------------
Task affs-predict:
num blocks : 9
completed ✔: 9 (skipped 0)
failed ✗: 0
orphaned ∅: 0
all blocks processed successfully
Task frags-extract-frags:
num blocks : 9
completed ✔: 9 (skipped 0)
failed ✗: 0
orphaned ∅: 0
all blocks processed successfully
Task fragments-aff-agglom:
num blocks : 9
completed ✔: 9 (skipped 0)
failed ✗: 0
orphaned ∅: 0
all blocks processed successfully
Task lut-graph-mws:
num blocks : 1
completed ✔: 1 (skipped 0)
failed ✗: 0
orphaned ∅: 0
all blocks processed successfully
Task pred_labels-relabel:
num blocks : 9
completed ✔: 9 (skipped 0)
failed ✗: 0
orphaned ∅: 0
all blocks processed successfully
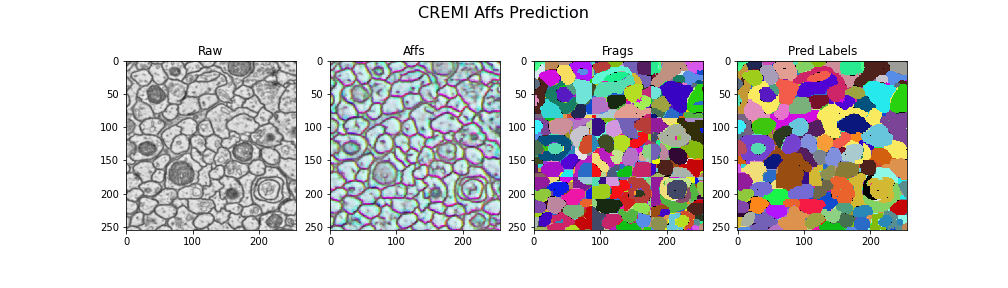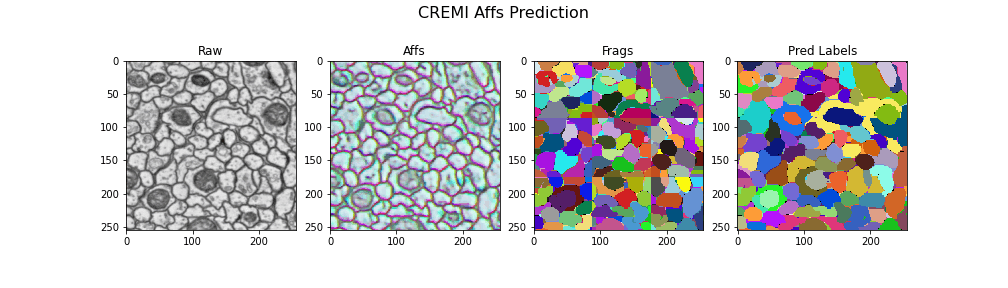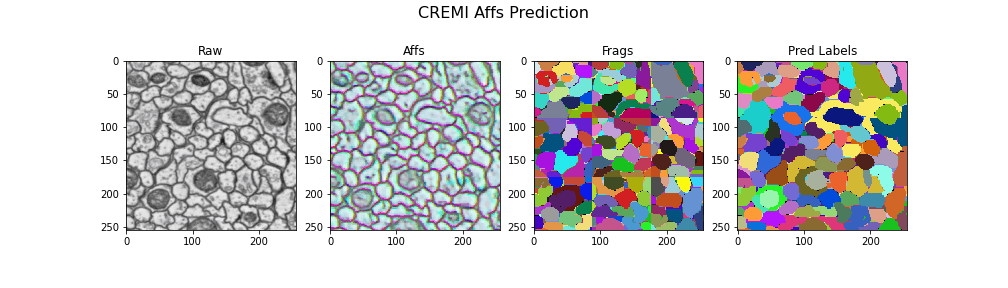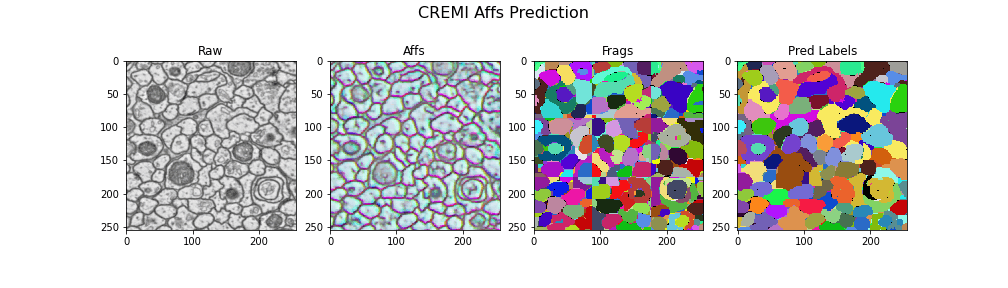
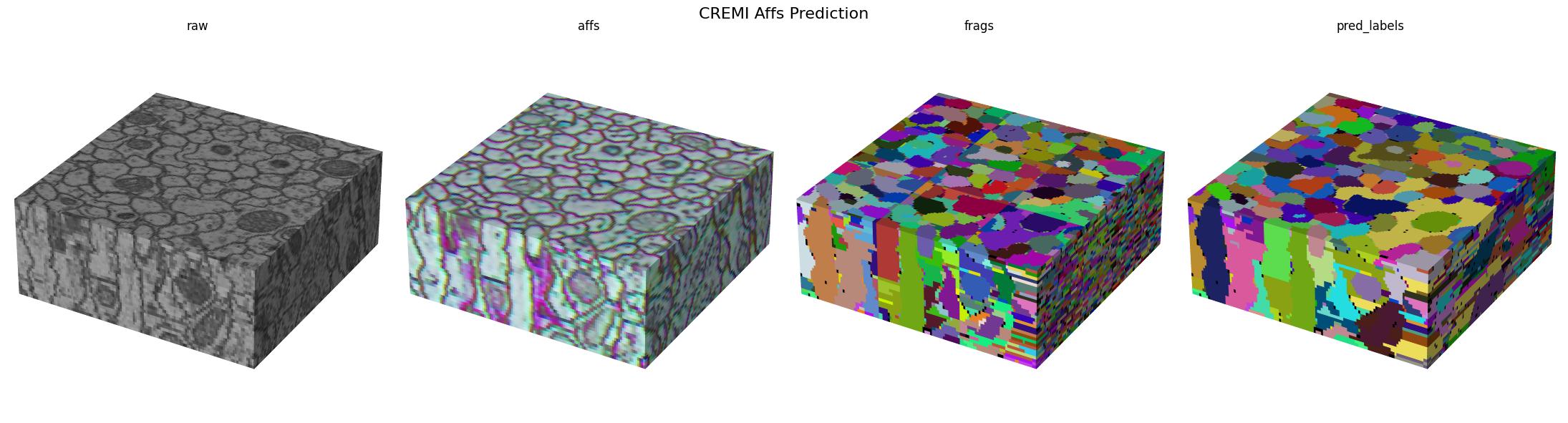
Visualizing the results
[17]:
from funlib.persistence import open_ds
affs = open_ds("cremi.zarr/test/affs")
affs.lazy_op(lambda x: x[[0, 3, 4]] / 255.0)
raw = open_ds("cremi.zarr/test/raw")
raw.lazy_op(large_eval_roi)
gif_2d(
arrays={
"Raw": raw,
"Affs": affs,
"Frags": open_ds("cremi.zarr/test/frags"),
"Pred Labels": open_ds("cremi.zarr/test/pred_labels"),
},
array_types={
"Raw": "raw",
"Affs": "affs",
"Frags": "labels",
"Pred Labels": "labels",
},
title="CREMI Affs Prediction",
filename="_static/cremi/cremi-prediction.gif",
fps=10,
)
cube(
arrays={
"raw": raw,
"affs": affs,
"frags": open_ds("cremi.zarr/test/frags"),
"pred_labels": open_ds("cremi.zarr/test/pred_labels"),
},
array_types={
"raw": "raw",
"affs": "affs",
"frags": "labels",
"pred_labels": "labels",
},
title="CREMI Affs Prediction",
filename="_static/cremi/cremi-prediction.jpg",
)
INFO:matplotlib.animation:Animation.save using <class 'matplotlib.animation.PillowWriter'>
Here we visualize the prediction results: